Czy marzyłeś/łaś kiedyś o budowie banku? Ja też nie
Budowa banku to zabawna rzecz. Bank to coś co utożsamiamy z korporacją, ze strukturami obejmującymi wiele poważnych osób oraz wreszcie z procedurami, które pokrywają wszystkie szczegóły i aspekty z którymi przychodzi nam się mierzyć. Nie ma tutaj miejsca na przypadek. Jednakże jeżeli budujesz taki bank, masz okazje zobaczyć na zaplecze… Dla mnie, po ponad 4,5 roku spędzonych w intive nad budową Tandem bank była to niezwykle fascynująca przygoda, ale zacznijmy od początku.
Zmiana planów
Trafiając do intive (wtedy jeszcze SMT Software) miałem pracować nad pewnym projektem, którego nazwy już nawet nie pamietam. Już pierwszego dnia współpracy okazało się, że nastąpiła ‚mała’ zmiana planów. Zaproponowano mi projekt Tandem, który potrzebował akurat nowych osób. Do dziś pamiętam w jaki sposób mój przyszły zespół został zaprezentowany – miałem wrażenie, że poszukiwana jest osoba z naprawdę dużym doświadczeniem, a uczestnictwo w projekcie to pewnego rodzaju prestiż. Nie wiem na ile były to umiejętności marketingowe managera, ale na prawdę chciałem się dostać! Pierwsza rozmowa z Tomkiem i Marcinem tylko utwierdziła mnie w przekonaniu, że chcę tam trafić. Chłopaki zaprezentowali mi projekt w taki sposób, że wiedziałem, iż nauczę się tu niewiarygodnie dużo – Event sourcing, architektura mikroserwisów komunikujących się zarówno sychronicznie jak i asynchronicznie, eventual consistency, 10+ nowych narzędzi do nauki… wchodzę w to!
Weekend
Weekend spędziłem na zgłębianiu tych zagadnień, gdyż następny etap to rozmowa z architektem Tandemu. Ten etap też poszedł bez problemu, aczkolwiek nieocenioną pomocą była poprzednia rozmowa z Marcinem i Tomkiem, który wprowadzili mnie w zagadnienia architektoniczne z któymi wcześniej się nie spotkałem w taki sposób, że ciężko było to zawalić. Stało się. Budujemy bank!
Budujemy bank!
Pierwsze zetknięcie z Tandemem to przede wszystkim natłok nowych rzeczy, nowi ludzie, nowe technologie, nowe procesy. To niebywałe jak szybko jesteśmy w stanie zaadaptować się do nowego otoczenia jeżeli sytuacja tego wymaga. To z czego najbardziej byłem zadowolony to ludzie. Współpraca z ludźmi profesjonalistami w swojej dziedzinie, którzy nie tylko są zaangażowani w rozwój projektu i swój, ale także są skorzy do pomocy to mieszanka wybuchowa. Dla mnie bomba! Moje pierwsze wrażenia z pracy to podekscytowanie tym nowym środowiskiem i możliwościami jakie tu są. Nie mogłem się doczekać by zacząć, umoczyć ręce w kodzie no i zbudować w końcu ten bank!
Pierwszy zespół w Tandemie to ‚black team’. Brzmi elitarnie, czyż nie? Dla mnie brzmiało, ale nazwa to tylko… nazwa. Przechodząc do rzeczy ważniejszych – stack technologiczny i wykorzystane podejścia architektoniczne wymagały ode mnie sporo nauki by wiedzieć w jaki sposób wykorzystywać to wszystko efektywnie. CQRS, Event sourcing, messaging, Event-Driven Architecture to była podstawa. Następne elementy układanki to kilka technologi o których wcześniej tylko czytałem lub słyszałem, takich jak NServiceBus, EventStore, Team City, Octopus deploy…. chyba nie ma sensu wypisywać wszystkiego.
Zadania w zespole?
agregacja danych z innych banków
wykrywanie regularnych płatności
najciekawsze highlighty dotyczące tychże kont bankowych
wyliczanie pieniędzy, które klient może bezpiecznie wydać w tym miesiącu
alarmy po przekroczeniu dolnego lub górnego progu bilansu konta
Lekcje
Jakie przemyślenia wyniosłem z tego począkowego okresu?
Lekcja 1.
Jeżeli jesteś wysoce zmotywowaną osobą i postawisz się w sytuacji, gdzie musisz nauczyć się wielu rzeczy to po prostu się ich uczysz. Przyparci do muru możemy osiągnąć na prawdę wiele. Dodatkowo wykrztałcamy w sobie umiejętność pracy w środowisku o podwyższonym poziomie niepewności. O ile łatwiej jest pracować nad czymś co znamy już od podszewki.
Lekcja 2.
Jesteśmy produktem środowiska w którym się znajdujemy. Twój progres opiera się w dużym stopniu o ludzi z którymi współpracujesz. W tym początkowym okresie było na prawdę łatwo o pozyskiwanie wiedzy od współpracowników, którzy odznaczali się z jednej strony błyskotliwością, ale z drugiej strony chęcią do dzielenia się wiedzą.
CDN
To tylko początek. W kolejnej części porównam doświadczenia w innych zespołach, a także projekty nad jakimi pracowałem. Oczywiście to oznacza jeszcze więcej lekcji, które wyciągnąłem.
Nie zawsze twój komputer jest na tyle wydajną maszyną by było to dla ciebie wygodne środowisko programistyczne. Czasami zdarza się tak, że trzeba sięgnąć jednak po coś szybszego. Nie zawsze chcesz kupować nowy komputer tylko na potrzeby jednego projektu, prawda? Niezależnie od powodów zakładamy, że skoro czytasz ten wpis to chcesz zająć się uczeniem maszynowym z Tensorflow na EC2 czyli AWSowym serwisem – Elastic Compute Cloud. Co więcej, będziemy chcieli by dostęp do systemu odbywać się przez GUI co daje o wiele większe pole manewru przy Machine Learning, który przecież może dotykać każdego medium, czy to tekst, dźwięk, obraz czy wideo.
Założenie konta nie powinno sprawić ci większych trudności. AWS dość dobrze i dokładnie tłumaczy jak to zrobić. Jeżeli dopiero teraz zakładasz konto, na pocieszenie pamiętaj o wykorzystaniu bonusów z AWS Free Tier https://aws.amazon.com/free/ . Jest to na prawdę ciekawa możliwość na przetestowanie wielu serwisów AWS-a przez pierwszy rok za darmo (a niektórych nawet dłużej niż rok). Oczywiście to ‚testowanie’ jest poddane ograniczeniom jednak często w zupełności wystarcza do stworzenia prostych serwisów. Ale teraz do meritum.
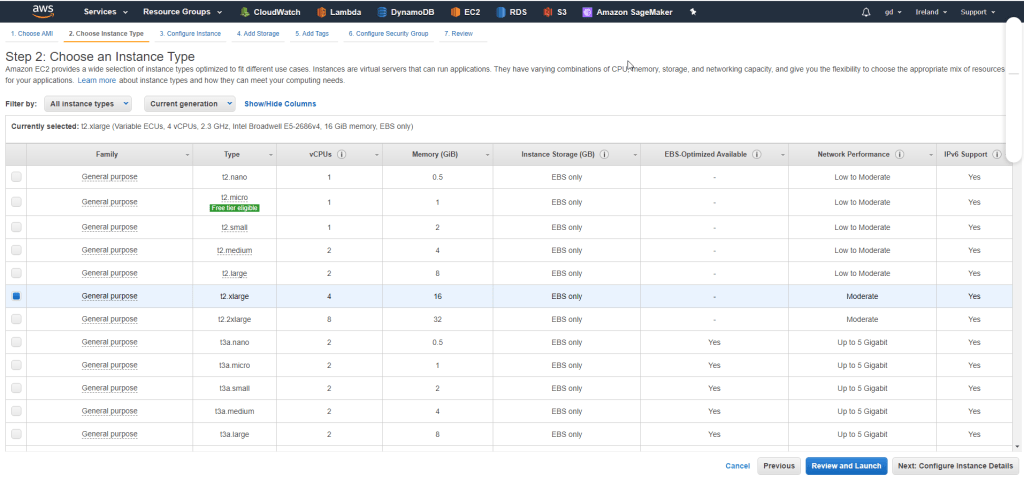
Zakładając, że masz już konto na AWS. Możemy przejść do ciekawszych spraw. W konsoli AWS, przechodzimy do serwisu EC2 i tworzymy nową instancję. Jaki region wybrać? Proponuje Frankfurt ew. Irlandia (prawy górny róg).
Wybór regionu
Przechodzimy do uruchamiania instancji.
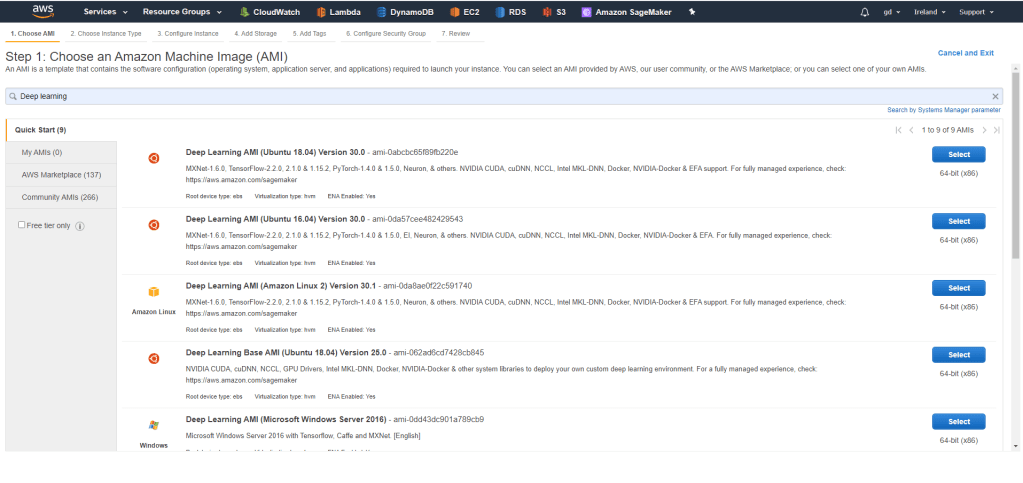
Naszym oczom ukazuje się obraz wyboru obrazu, którego chcemy użyć. Wybieramy odpowiedni AMI, czyli Amazon Machine Image. Wpisujemy w pole wyszukiwania ‚Deep Learning’. To specjalnie przygotowane obrazy z narzędziami do Machine Learning jak np. tytułowy Tensorflow. Oczywiście moglibyśmy zainstalować wszystko od zera. Moglibyśmy też kupić sobie maszynkę i nie używać chmury itd… 🙂 W każdym razie, powinniśmy zobaczyć ekran:
Ja np. wybrałem maszynkę z najnowszym Ubuntu i jeżeli nie masz swoich preferencji to wybierz ją także.
Rodzaj instancji
Kuszące może być skorzystanie z wersji ‚micro’ by wykorzystać ww. Free Tier. Jednak szczerze to odradzam tego rodzaju skąpstwo. Używamy AWS gdyż zapewnia nam wygodne skalowanie maszyny do problemu, ale na maszynie ‚micro’ raczej nie rozwiążemy żadnego problemu. Na początek możesz wybrać np. t2.xlarge. Jest to instancja generalnego przeznaczenia i traktujemy ją jak playground. Później w każdej chwili możemy przesiąść się na coś bardziej dedykowanego pod Machine Learning. Pamiętaj, żeby przed użyciem maszyny zapoznać się z cennikiem, tak żeby nie było, że nie uprzedzałem https://aws.amazon.com/ec2/pricing/
Warto nadmienić, że w następnym wpisie mogę pokazać ci jak znacząco ograniczyć koszta poprzez wykorzystanie tzw. ‚spot instances’ jednak tutaj nie chcę nadmiernie komplikować rozwiązania. Klikamy kolejno na ‚Review and Launch’ I potem ‚Launch’
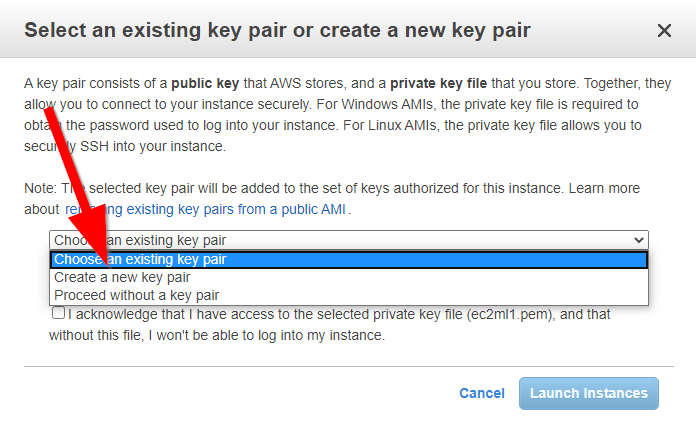
Credentials
Dobrą praktyką będzie stworzenie osobnych kluczy, wybieramy ‚Create a new pair’
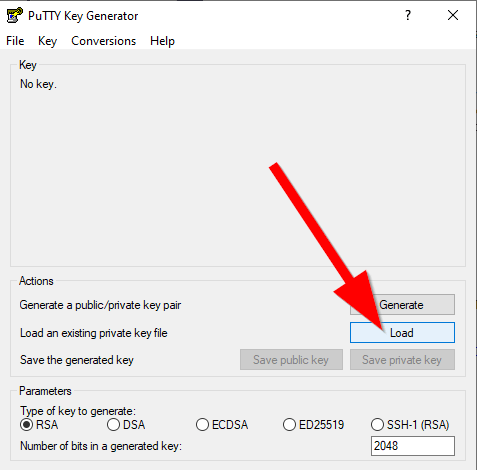
Jeżeli teraz spróbujemy użyć kluczy, możemy napotkać na problem z kompatybilnością ich formatu. Jeżeli tak się stanie, a dla mnie się to stało, to będziemy potrzebować aplikacji putty https://www.putty.org/ więc proszę ściągnij ją. Odpalamy narzędzie puttygen.exe przychodzące w zestawie z putty i ładujemy klucz ściągnięty z AWSa.
I zapisujemy w formacie ppk. Uff mamy klucz do drzwi. Ale gdzie są drzwi???!
Wracamy do naszej świeżo wypieczonej instancji EC2. Na stronie z instancjami EC2 mamy na dole panel ze szczegółami dotyczącymi naszej instancji. Nas przede wszystkim interesuje adres publiczny IP i adres prywatny IP. To przez te adresy spróbujemy połączyć się z naszego komputera do instancji.
Putty
Tak, zwracamy się o pomoc do Pana Putty.
Naszym oczom ukazuje się ekran niczym z … dobra nie hejtujmy, putty to na prawdę świetne rozwiązanie.
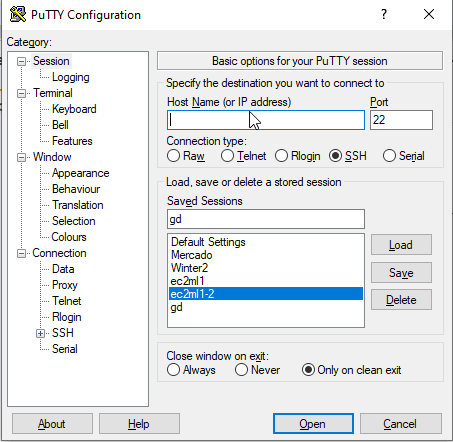
w pole Host Name wpisujemy nasz publiczny adres i przechodzimy do Connection>SSH>Auth i klikamy Browse wybrać klucz który uprzednio skonwertowaliśmy
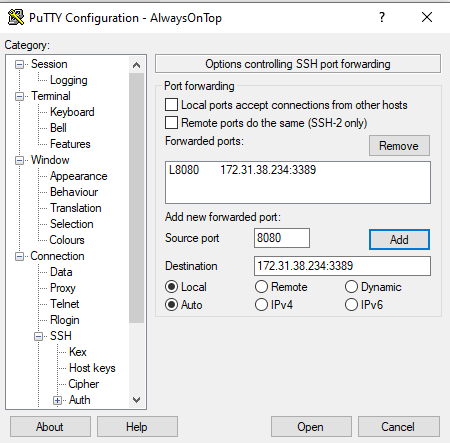
Teraz otwieramy zakładkę ‚Tunnel’ i tworzymy tunel do naszej instancji, jako port źródłowy podajemy dowolny wolny port, u mnie np. 8080 i jako cel tunelu: prywatne IP instancji EC2 oraz port 3389. Dzięki temu ruch na nasz localhost:8080 zostanie przekierowany przez Putty do AWS do naszej prywatnej maszynki przez port 22 na adres prywatny i port 3389 (RDP).
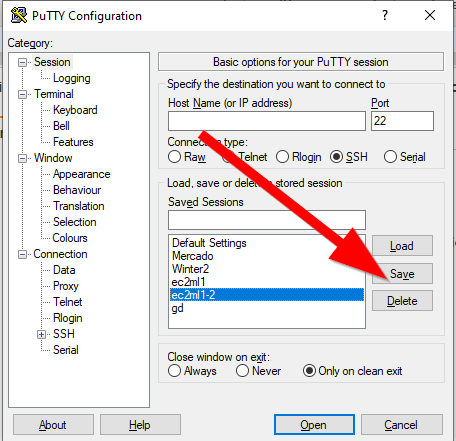
Ważna sprawa, po każdej zmianie zapisujemy sesję, by nie stracić dotychczasowego nakładu pracy:
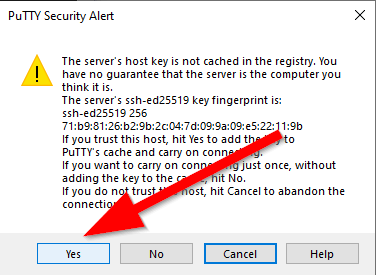
Dobra ale nasza instancja nie jest jeszcze gotowa by pokazać swój desktop. By ją do tego przygotować otwieramy naszą sesję (Open) i pokaże nam się okno w stylu:
Przy pierwszym połączeniu jest to oczekiwany rezultat. Przechodzimy dalej klikając Yes.
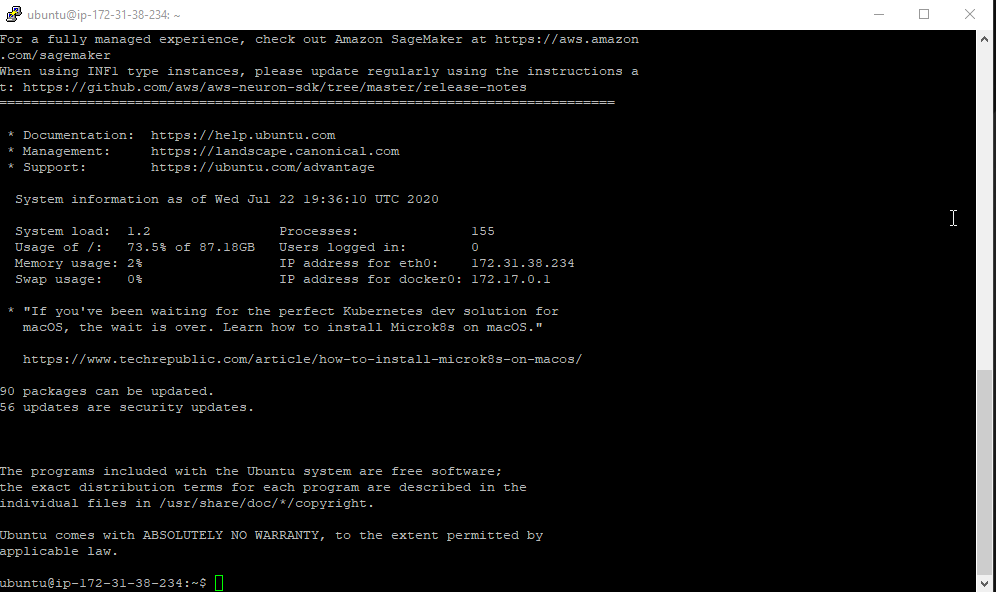
Na następnym ekranie wita nas już terminal naszego systemu. Login to: ubuntu Jeżeli widzisz ekran taki jak
to brawo, udało się, jesteśmy połączeni. Teraz możemy przystosować naszą instancję by umożliwić tryb GUI.
Pamiętaj żeby zachować hasło, które podasz za chwilę, w przeciwnym wypadku połączenie będzie niemożliwe.
Po wykonaniu powyższych instrukcji przystępujemy do ostatniego etapu. Uruchamiamy Remote Desktop Connection (RDP) i podajemy adres localhost:8080 (lub jakikolwiek inny port skonfigurowany w putty)
Mamy to! Tryb GUI na AWS EC2!
Tak wygląda ekran naszego ubuntu
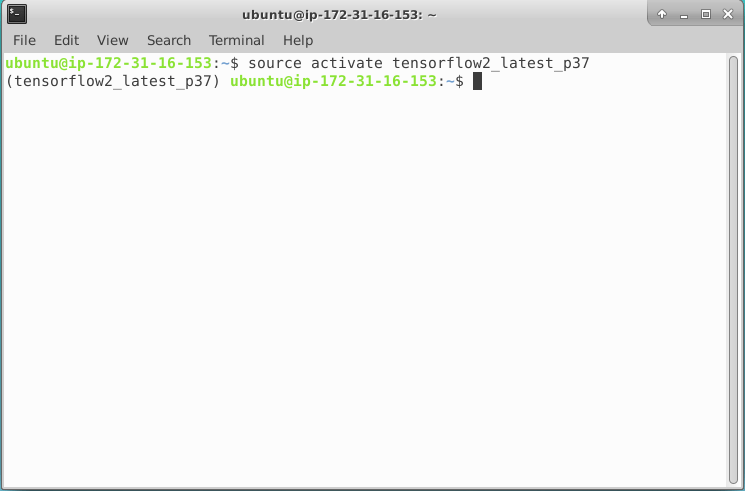
Jeszcze tylko włączmy odpowiednie środowiko uczenia maszynowego i jesteśmy w domu. Przebyliśmy dziś długą drogę, ale na szczęście aktywacja Tensforflow na naszej maszynie będzie bardzo prosta dzięki obrazowi (AMI), który wybraliśmy (Deap learning). Wykorzystujemy najnowszą wersję Tensorflow przy użyciu:
source activate tensorflow2_latest_p37
i w konsoli możemy już zaczynać pracę.
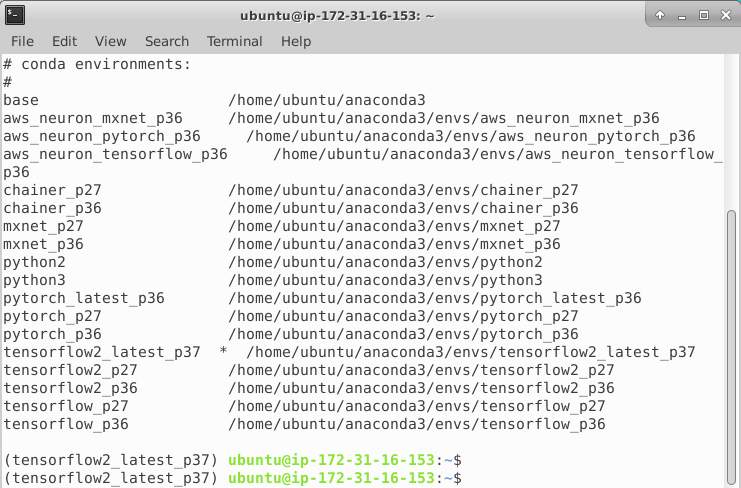
Jeżeli wolisz jakąś inną wersję Tensorflow-a, bądź też całkiem inny pre-instalowany framework, zawsze możesz wykorzystać komendę listującą dostępne środowiska i wybrać coś innego:
Po wyborze i aktywacji odpowiedniego środowiska możemy przetestować, że wszystko poszło po naszej myśli. W moim wypadku w konsoli python-a wpisuję:
import tensorflow
print(tensorflow.__version__)
Wszystko gra. Przed nami otwierają się nowe możliwości.
Jednym z pierwszych wyzwań stojących przed mikroserwisami jest wybór sposobu komunikacji.
Wybór rodzaju interakcji
Wybierając odpowiedni w danym przypadku styl interakcji musimy zbadać jakiego rodzaju komunikacją mamy do czynienia. Mamy tutaj do wyboru:
Jeden do jednego – inicjator wykonuje żądanie, które jest przetwarzane przez dokładnie jeden serwis odbierający żądanie
Jeden do wielu – w tym modelu wiadomość może być przetwarzana przez wiele serwisów odbierających (w szczególnym wypadku może być to jeden lub zero serwisów). Zazwyczaj dla serwisu inicjującego konwersacje, będzie transparentne to ile serwisów przetwarza to żądanie
Styl interakcji
Wybór stylu interakcji sprowadza się do pytania czy komunikacja ma charakter synchroniczny czy asynchroniczny:
Komunikacja synchroniczna – inicjator czeka na odpowiedź
Komunikacja asynchroniczna – inicjator nie czeka na odpowiedź
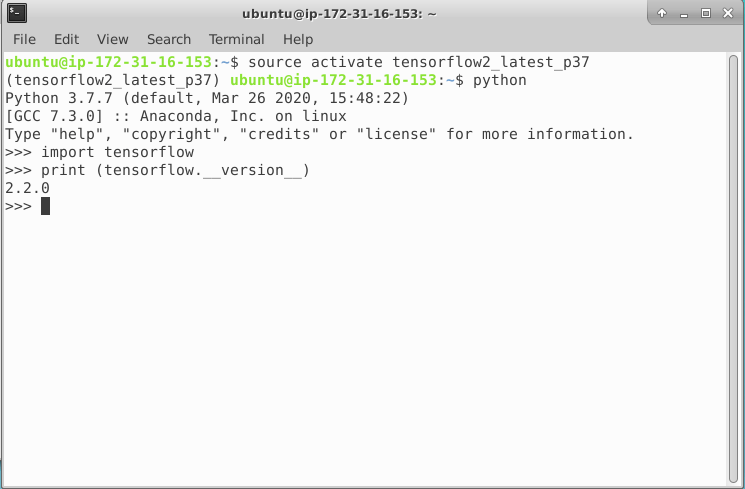
Odpal i zapomnij (ang. fire-and-forget) – inicjator konwersacji wysyła wiadomość, która dociera do odbiorcy. I to w zasadzie tyle. Ciężko sobie wyobraźić prostszy schemat konwersacji.
Zapytanie/odpowiedź – najczęściej stosowana metoda interakcji. Strona inicjująca odpytuje drugą i czeka na odpowiedź, która powinna pojawić się w określonym czasie.
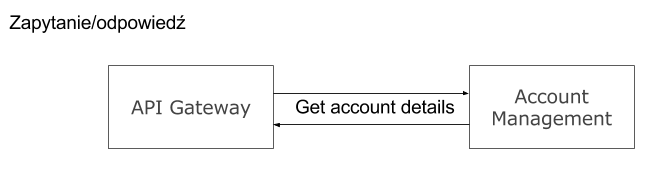
Zapytanie/asynchroniczna odpowiedź – polega na wysłaniu zapytania przez klienta do serwisu, który odpowiada asynchronicznie. Jakie ma to implikacje? Otóż klient może w sposób nieblokujący czekać na odpowiedź. Nic nie stoi na przeszkodzie by w tym czasie robić inne obliczenia. Do klienta należy obsługa całkiem prawdopodobnej sytuacji, iż takiej odpowiedź nie dojdzie.
Publikacja/subskrypcja – przesyłanie wiadomości polega tutaj na udostępnianiu informacji przez publikatorów, a ich odbiorcami są wszystkie jednostki w systemie, które są zainteresowane danym komunikatem.
Technikalia
Posiadając do wyboru kilka możliwych wzorców interakcji musimy zdecydować się jeszcze na techniczne szczegóły co do sposobu w jaki taka interakcja zostanie zrealizowana.
By zapewnić jak najlepszą niezawodność systemu przy wysokiej wydajności i skalowalności, najczęściej najlepszym wyborem będzie kombinacja technologii komunikacji. W różnych miejscach systemu możemy zastosować różne sposoby komunikacji:
HTTP/REST API
Wiadomości (messaging)
Inny, specyficzny dla domeny protokół komunikacji
W zależności od tego który ze sposobów komunikacji wybierzemy musimy liczyć się z konsekwencjami. I tak:
Szybki, elastyczny sposób na implementację komunikacji pomiędzy serwisami. Dla większości programistów będzie to także po prostu najprostsze w użyciu narzędzie. Często wykorzystywany do wykonywania zapytań (w odróżnieniu do komend). Dużym plusem jest brak narzutu co do konkretnej technologii. Serwisy wykorzystujące komunikację poprzez HTTP/REST API mogą korzystać z szerokiej gamy rozwiązań. Co najważniejsze, nie ma problemu by po obu stronach komunikacji występowały całkowicie różne technologie.
Ta technologia, w najprostszej wersji, charakteryzuje się synchronicznością działania co w zależności od kontekstu będzie zaletą bądź też wadą. Dzięki powszechnej znajomości tego rozwiązania zazwyczaj nie będzie problemu z zastosowaniem tego rozwiązania. Definitywnym minusem tego rozwiązania jest wrażliwość na problemy z dostępem do sieci, w chwili wykonywania zapytania obie strony interakcji muszą działać. Inną wadą jest wymaganie znajomości adresu serwisu przez klienta. Intuicyjnie może to nie wydawać się jak duży problem, aczkolwiek skalowanie systemu wymaga od nas by klient mógł i wiedział jak może połączyć się z wszystkimi instancjami danego serwisu.
2. Wiadomości (messaging)
Wymiana informacji pomiędzy serwisami za pomocą wiadomości to świetny sposób na rozluźnienie powiązania pomiędzy nimi. Ta, z natury asynchroniczna, komunikacja polega na tym, że jedna ze stron komunikacji zapisuje wiadomość, natomiast druga ją odczytuje. Dobrze to współgra z wzorcami architektonicznymi takimi jak CQRS i EDD (Event-Driven Development). Decydując się na ten sposób komunikacji, musimy podjąć decyzję jakiej technologii użyjemy. Przykładowymi, popularnymi rozwiązaniami są: Apache Kafka, AWS Kinesis Streams, Azure Service Bus, RabbitMQ, NServiceBus, MassTransit, MSMQ. Wspomniane rozwiązania różnią się znacznie podejściem do architektury systemu, poziomem abstrakcji i sam opis tychże różnic to spory temat. Dodatkowo mamy tutaj spory wachlarz wzorców komunikacji jak np. : publikacja/subskrypcja czy też zapytanie/odpowiedź. Możemy tutaj uzyskać wysoką skalowalność jak i wysoką dostępność systemu za cenę dodatowej złożoności systemu spowodowanej wykorzystaniem infrastruktury umożliwiającej komunikację przez wiadomości.
3. Specyficzny protokół komunikacji taki przesył danych binarnych, JSON czy też XML.
Czasami sytuacja zmusza lub też zachęca nas do użycia jakiegoś innego formatu danych. Często jest to uwarunkowane specyficznymi wymaganiami w konkretnej domenie i umożliwia to np. wydajny streaming multimediów.
Komunikacja między serwisami wymaga od nas znajomości charakteru interakcji co potem wpływa na wybór technologii. Każda z tych decyzji niesie za sobą zalety ale i wady, ale mając ich świadomość jesteśmy w stanie zbudować system, który w wydajny sposób się komunikuje i wykorzystuje infrastrukturę by uzyskać zarówno wysoką dostępność jak i niezawodność.
Zaparzasz poranną filiżankę kawy. Kenijskie ziarno nadaje jej niezwykle pobudzający, ale i rześki aromat. Mijając okno, rzucasz krótkie spojrzenie na zewnątrz. Cóż za cudowny, słoneczny poranek! Jakieś wewnętrzne ciepło mówi ci, że to będzie dobry dzień. Powoli zbliżasz się do biurka, zastanawiasz się co ciekawego dziś cię czeka, jakie wyzwania rzuci ci los. Po kilku minutach spędzonych na poszukiwaniu odpowiedniego zadania trafiasz na coś co nie wygląda tak źle. Nie jest to coś super trudnego, nie jest to coś banalnego. Idealne zadanie na poniedziałkowy poranek. Otwierasz kod projektu i już od początku czujesz to okropne uczucie obrzydzenia. Spod dziesiątek linijek kodu wydobywa się odór zastanego kodu. Tak, to śmierdzi kod legacy.
Wtorek
Wczorajszy dzień nie był zbyt udany. Może i wymagana zmiana nie wydaje się zbyt trudna, ale nasuwa się pytanie w którym miejscu należy jej dokonać. Pierwsze próby nie przynoszą spodziewanego efektu. Pytasz ludzi z zespołu o wskazówki lecz okazuje się, że wszyscy, którzy mieli do czynienia z tą funkcjonalnością już dawno odeszli. W myślach zastanawiasz się czy odeszli czy też uciekli w popłochu? Kolejny dzień samotnej walki przed tobą.
Środa
Udało się okiełznać potwora. W myślach co prawda już trzy razy składasz rezygnację i rzucasz papierami, ale być może obejdzie się tym razem bez tego? Kilka if-ów umiejętnie wstrzykniętych w odpowiednie miejsca wydaje się robić robotę. Może nadal nie masz do końca pojęcia co robisz, ale wyniki są dość dobre. Postanawiasz napisać testy. Unit testy to jest to! Po pierwsze pozwolą na lepsze zrozumienie funkcjonalności, a po drugi zapewnią pokrycie warunków brzegowych. Zderzenie z rzeczywistością jest jednak dość brutalne. Autor kodu nie był fanem testów jednostkowych. Albo inaczej, może i był fanem, ale akurat tutaj nie przewidział możliwości wstrzykiwania zależności. No cóż, następnym razem na pewno się uda. Tymczasem postanawiasz uporządkować kod i stworzyć Pull Request. Od razu znajdujesz kilka pomysłów jak niskim kosztem ulepszyć kod w okolicy twoich zmian lecz czy warto ponosić ryzyko bez testów jednostkowych? Racja, lepiej się nie wychylać, jest stanowczo zbyt wiele do stracenia. Wygrywa opcja „Pull request i fajrant”.
Czwartek
Na spotkaniu zespołu podnosisz temat czasu potrzebnego na refaktoring funkcjonalności z którą właśnie się ścierasz. Jak mityczni „oni” mogli stworzyć takie gówno? „To trzeba zaorać i przepisać”. Twój zespół potakująco kiwa głową, patrząc z boku ma się wrażenie, że jesteście na koncercie rapowym. Potrzebujesz tygodnia, dwóch, góra trzech i „będzie Pan Product Owner zadowolony”. Pan Product Owner przynajmniej na razie nie podziela jednak twojego entuzjazmu. Jak usłyszał o tym, że potrzebujesz nawet 3 tygodni na to by spędzić czas na czymś co nie przyniesie żadnego namacalnego efektu to o mało nie spadł z krzesła. Na szczęście dzięki poparciu innych członków zespołu udało się wynegocjować częściowy refaktoring. Co prawda ograniczony do tygodnia, i nie teraz tylko za sprint lub dwa. Uznajesz to za sukces. Szybko jednak zostajesz zawalony stertą innych zobowiązań, oczywiście wszystko na ASAP. Na szczęście Pan Product Owner zapewnia, że to tylko tymczasowe i że jak się już odkopiecie z ASAPów to będzie chwila na odetchnięcie i refaktoring. To będzie twoja chwila by pisać idealny, skalowalny, czysty kod.
Piątek
Zaczyna do ciebie docierać, że historia zaczyna zataczać koło. Że kiedyś już Pan Product Owner zbywał twoje sugestie o refaktoring. Piątek, piąteczek, piątunio to idealna okazja do refleksji. Tematem refleksji jest „co poszło nie tak?”, „czy refaktoring to słowo tabu?” oraz „jak mieć/zdobyć czas na refaktoring?”
No właśnie, odpowiedzmy sobie na po kolei na pytania.
Odsuwanie niezbędnych zmian w kodzie, zaniedbania doprowadzające go do złego stanu i wrażenia „kodu legacy” to choroba która zaczyna się niewinnie. Tutaj magiczna liczba, tutaj dodatkowy „if”, tutaj przekopiowana metoda. Samo w sobie nic z tego nie jest problematyczne, problematyczne jest to, że każde takie małe uchybienie bez stałej pracy o to by poprawiać jakość kodu, prowadzi w tempie błyskawicznym to degradacji jakości kodu. Składają się na to 3 główne czynniki:
tzw. efekt zbitych okien, czyli łatwiej jest wprowadzić „brzydką” zmianę jeżeli kod już zawiera inny „brzydki” kod, w końcu to nie my zaczęliśmy tą karuzele degradacji, prawda?
złożoność kodu zależy od jakości ale też i od objętości kodu. Dodając nowe linijki łatwo jest skomplikować kod. Reguła kciuka w tym wypadku mówi nam by w miarę możliwości dodawać tego kodu jak najmniej. Każda nowa linijka to potencjalny bug, to kolejna linijka która musi być przeczytana przez osobę czytającą kod i starającą się go zrozumieć
im trudniejszy do zrozumienia kod, tym mniejsza szansa że osoba robiąca zmiany po nas będzie miała odwagę by go poprawić
Czy refaktoring to słowo tabu?
Refaktoring to może być dla naszego rozmówcy słowo-trigger. Warto przemyśleć czy to słowo nie ma negatywnych skojarzeń dla osoby z którą dyskutujemy. Ja staram się nie być uprzedzony, ale trudno nie oprzeć się wrażeniu, że o refaktoringu mówią często osoby, które niekoniecznie mają kompetencje by go umiejętnie przeprowadzić. Wg mnie warto tutaj po prostu używać pełnej definicji refaktoringu i mówić o tym jaki efekt chcemy uzysać, czyli np. „chcemy zmienić istniejący kod w taki sposób aby zredukować jego złożoność oraz zmieniejszyć koszt wprowadzania nowych zmian, bez zmiany istniejącej funkcjonalności”.
Jak mieć/zdobyć czas na refaktoring?
To zdecydowanie najważniejsze pytanie. Odpowiedź dla niektórych może wydawać się też zaskakująca. Może rzeczywiście w naszym wypadku to Product Owner ma rację ze swoją wstrzemięźliwością co do refaktoringu? Najłatwiej i najefektywniej, zmiany refaktoryzujące, wprowadzać jako część standardowego procesu implementacji nowych funkcjonalności czy też poprawiania błędów. Wprowadzanie osobnego czasu tylko i wyłącznie na refaktoring to ostateczność. Argumenty? proszę bardzo:
redukujemy ryzyko związane z wprowadzaniem wielkich zmian. Znacznie łatwiej coś popsuć jeżeli zmieniasz 500 linijek niż gdy zmieniasz 15 lub 50, prawda?
wprowadzamy zmiany wokół funkcjonalności, która w danym momencie jest przez nas analizowana. Oznacza to, że jest to kod który dokładnie zrozumiany i nasze zmiany będą tam najbardziej przemyślane i sensowne
nie chcemy być postawieni pod ścianą. Zdarzają się sytuacje w postaci krytycznych błędów, kiedy musimy poprawić coś jak najszybciej. Nie chcielibyśmy by taka sytuacja stała się w chwili tuż przed planowanym refaktoringiem kiedy mamy do czynienia z kumulacją niedoskonałości kodu nagromadzoną przez dłuższy czas
pokazujemy naszą incicjatywę, jako programista odpowiadamy za jakość tego co wytwarzamy. Jasne, że fajnie jest mieć wymówki, że „mogłem to zrobić lepiej ale mi nie pozwolili”, ale koniec końców to my będziemy musieli się męczyć z tym kodem.
kod legacy, który przebył już kilka cykli naprawiania w nim błędów, może zwyczajnie posiadać w sobie więcej wiedzy niż jesteś w stanie zrozumieć. Nawet jeżeli kod jest brzydki to często nie ma sensu go ruszać, zwłaszcza jeżeli działa dobrze i w najbliższej przyszłości nie planujemy wprowadzać tam nowej funkcjonalności
unikamy niepotrzebnych rozmów nt. tego czy potrzebujemy refaktoringu. Jeżeli jesteś pewien/pewna, że dany fragment kodu wymaga refaktoringu, to go robisz. Zakładając ciągłą troskę o kod, ta decyzja jest szybka (oszczędzamy czas potrzebny na osądy), zmiana jest skuteczna i mała (ograniczone ryzyko że coś pójdzie nie tak). Na pewnym poziomie doświadczenia jest to krytyczna umiejętność profesjonalnego programisty by zrobić dokonać zmiany popychającej kierunek projektu w dobrym kierunku, kawałek po kawałku.
Refaktoring to na prawdę romantyczna wizja w której siadasz do kodu i zamieniasz coś czego trzeba się wstydzić, na coś co spełnia twoje standardy czystego kodu. Nie trzeba się temu dziwić w końcu w każdym z nas jest przynajmniej trochę takiego wewnętrznego artysty, który chce stworzyć coś swojego i nadać temu pożądany kształt. Po spotkaniu z rzeczywistością jednak często okazuje się że może nie być to najefektywniejszy sposób pracy. O wiele skuteczniejszą metodą niż jednorazowe podrywy refaktoryzujące może okazać się zwykła codzienna troska o jakość dostarczanych rozwiązań. Kto powiedział że nie możemy robić mini-refaktoringu codziennie?
Skoro już cię przekonałem dlaczego warto używać chmury oraz dlaczego to może być AWS następnym logicznym krokiem jest przedstawienie jakiegoś przykładowego rozwiązania bazującego na chmurze AWS. Dziś na warsztat weźmiemy rozwiązanie streamingowe, które pozwoli ci pobić Netflixa 😉
Domena
Dla uproszczenia dziedziny problemu, przyjmijmy, że chcielibyśmy mniej więcej odzwierciedlić podstawowe funkcjonalności Netflixa (oczywiście zrobimy to lepiej!), czyli dostarczyć rozwiązanie pozwalające na oglądanie wideo na życzenie oraz platformę, która owe wideo serwuje. Użytkownik w dzisiejszych czasach jest bardzo wybredny. Mając do czynienia z rozwiązaniami typu HBO Go czy Netfix musimy dostarczyć serwis, która będzie:
Niezawodny
Powiedzmy sobie szczerze ile razy nie działał ci Netflix z ich winy?
Szybki
Jeżeli użytkownik będzie musiał czekać na buforowanie wideo zbyt długo to pójdzie tam gdzie nie musi czekać. To nic osobistego.
Relatywnie tani
Oczywiście możemy kupić najlepsze dostępne serwery, bazy danych itd, ale kiedy przyjdzie nam obsługiwać ruch tysięcy użytkowników to rachunki szybko poszybują na poziomy takie, że szybko zrezygnujemy z naszych ambitnych planów.
Skalowalny
Użytkownika mało obchodzi to, że akurat dziś ruch na naszych serwerach jest 2-3 czy 10 razy większy niż zwykle. To się zdarza, naszym zadaniem jest na to się przygotować.
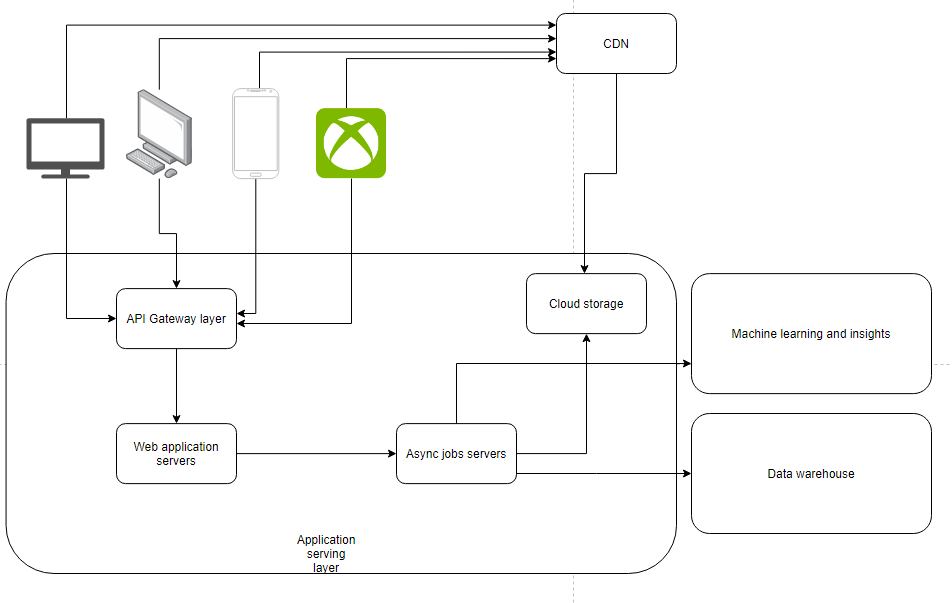
Ogólna architektura
Pomijając zbędne szczegóły architektura takiego przekrojowego rozwiązania może wyglądać następująco:
Omówmy sobie po kolei wszystkie komponenty
Warstwa API Gateway
Odpowiada za odbiór żądań ze strony urządzeń. Jak mówi nazwa to interfejs do naszego systemu. Wszelkiego rodzaju przeglądarki, smartfony czy też TV będą komunikować się właśnie przez tą warstwę. Tutaj załatwimy sprawę cache-owania żądań, kontroli dostępu i przekierujemy żądania do warstwy serwerów aplikacyjnych.
Warstwa serwerów aplikacyjnych
Tutaj umieścimy obliczenia i całą logikę odpowiedzialną za obsługę żądań. Główny kod odpowiedzialny za synchroniczne przetwarzanie zapytań tak by dostarczyć użytkownikowi odpowiednie „ekrany” i ich zawartość. Od strony infrastruktury, logika odpalana jest oczywiście na serwerach czy też ich klastrach. Częściowo mogą być to lambdy przy podejściu bardziej serverless. Zwłaszcza na początku gdy dopiero rozpatrujemy różne możliwości jest to kuszące rozwiązanie. Mamy tu także wykorzystanie kolejek zadań, cache, baz danych, oraz oczywiście innych mikroserwisów czy to naszych, czy też zewnętrznych rozwiązań – SAAS.
Warstwa zadań asynchronicznych.
Wszystkie zapytania, które nie należą do naszej aplikacji bezpośrednio, ale też muszą się zadziać. Jeżeli chcesz zrobić system chociaż w niewielkim stopniu podobny do Netflixa, czy też go pobić, trzeba sobie uświadomić sobie ogrom pracy jaka jest wykonywana „pod spodem”, czyli po prostu na backendzie.
Co musimy przygotować dla użytkowników?
Wideo w odpowiednim formacie. Każde urządzenia to inne wymagania odnośnie formatu czy też rozmiaru. Nie mówiąc o tym, że musimy serwować różne pliki w zależności od szybkości łącza użytkownika.
Rekomendacje. Kiedyś to może byłby fajny dodatek, teraz to wymóg by prezentować rekomendacje dla użytkowników, jeżeli trafimy w gusta, +5 punktów dla nas!
Newslettery. Byle nie za dużo spamu.
Bieżąca obsługa. Reset hasła, usunięcie konta itd
Przestrzeń chmurowa (cloud storage) i CDN
Forma przechowywania danych wideo to jedno z bardziej krytycznych zadań. Trzeba pamiętać o tym, że danych tych będzie bardzo dużo (pamiętasz, że mamy wiele kopii tych samych filmów?) Potencjalne koszty będą tutaj silnie skorelowane właśnie z rozmiarem danych. Z drugiej strony nie możemy sobie pozwolić by dostęp do nich był wolny, inaczej użytkownik szybko wybierze konkurencję. Innymi słowy potrzebujemy hybrydy przestrzeni chmurowej i CDNa. Przestrzeń chmurowa to po prostu serwer plików, a CDN, czyli Content Delivery Network lix-a to rozproszona sieć buforująca często używane zasoby poprzez ich kopiowanie na odpowiednie serwery będące blisko użytkownika końcowego. Będąc w Polsce, możemy szybciej streamować film, jeżeli znajduje się od na serwerze we Wrocławiu, niż gdy znajduje się w Los Angeles, prawda?
Uczenie maszynowe
Tutaj umieszczamy cokolwiek, byle by móc powiedzieć, że „robimy machine learning” i ściągnąć zainteresowanie inwestorów i klientów 😛 A tak na prawdę to skoro chcemy serwować naszym użytkownikom wspomniane wcześniej rekomendacje to dobrze jest móc to robić w oparciu nie o sztywne reguły, a właśnie modele wykorzystujące uczenie maszynowe. Dzięki temu będziemy mogli analizować podobieństwo między różnymi użytkownikami oraz podobieństwo miedzy filmami i na tej podstawie decydować czym dana osoba może być zainteresowana. To wszystko powinno przełożyć na trafniejsze rekomendacje i wzrost zainteresowania naszym rozwiązaniem.
Hurtownia danych
Raporty, analiza danych, musisz trzymać rękę na pulsie. Hurtownia to miejsce gdzie dane te są zorganizowane w przystępnej formie.
AWS
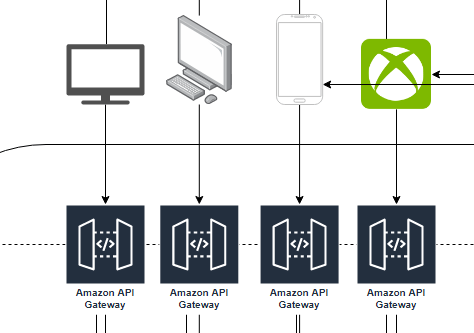
Przestwawię teraz przykładową implementację powyższych komponentów w AWSie. Od razu zaznaczam, że pewne kwestie zostały pominięte dla prostoty diagramu, przykładowo logowanie czy monitoring. Jeżeli chodzi o dobór konkretnych rozwiązań to też mamy do wyboru wielorakie rozwiązania na rynku. Nic nie stoi na przeszkodzie by część z nich było poza AWS, jednak formuła tego artykułu jest taka, że tylko do tej chmury zawęzimy nasz wybór. Dobra, koniec gadania:
Jak wcześnieś zauważyliśmy, chcemy odpowiednio zopytmalizować wrażenia użytkowników różnych platform. Stąd też podejście typu backend for frontend, czyli warstwa API Gateway posiada wyspecjalizowane dedykowane AWS API Gatewaye w zależności od platformy klienckiej.
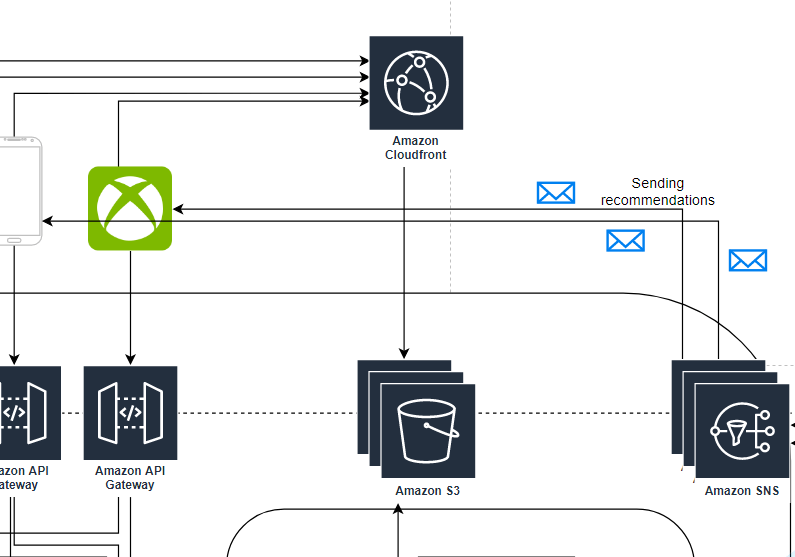
Warstwa serwerów aplikacyjnych
Sercem rozwiązania są klastry ECS, czyli Elastic Cloud Server. Tak, konteneryzacja zawitała i do nas! Żądania przychodzą od strony load balancer-a. Do tego SQS do kolejkowania zadań. Jako baza danych może posłużyć nam DynamoDB o ile dobrze czujemy się w środowisku baz NoSQL. Zaletą DynamoDB jest łatwa skalowalność, która jest dla nas niemalże przeźroczysta. Alternatywnie możemy posłużyć się RDS Aurorą.
Od strony infrastruktury wygląda to podobnie jak w przypadku warstwy serwerów aplikacyjnych. Różnicą będzie dużo większe wykorzystanie kolejek SQS, potencjalnie także topic-ów SNS to komunikacji zorientowanej na wiadomości, której będzie tutaj dużo.
Jedno z kluczowych zadań do wykonania w tej warstwie to transcoding wideo, który może wyglądać następująco:
Na wejściu mamy nieskompresowany plik wideo, wrzucony być może przez samego autora filmu. Na wyjściu mamy plik dostosowany przez nas process do odpowiedniego urządzenia końcowego.
Przestrzeń chmurowa (cloud storage) i CDN
Troche już w punkcie poprzednim zostało opowiedziane przy okazji omawiania transcodingu. S3+CloudFront załatwiają sprawę.
Z naszej perspektywy użyteczne mogło by być zwłaszcza AWS Elemental MediaConvert, które zapewnia właśnie usługę transcodingu. Dużym plusem jest to, że płacimy tutaj za użycie, czyli tak jak w infrastrukturze powyżej, gdzie brudną robotę wykonują za nas EC2-ki. Myślę, że AWS Elemental MediaConvert możemy rozważyć jako element naszego MVP a docelowo możemy kierować się jednak ku ECS/EC2 gdyż pozwoli nam to na większą elastyczność rozwiązania i zoptymalizowanie kosztów. Zasadniczo reguła kciuka mówi nam, że im bardziej wysokopoziomowe rozwiązanie, tak jak w przypadku AWS Elemental MediaConvert, cena rośnie w sposób adekwatny.
Podsumowanie i dalsze kroki
Tak jak pisałem wyżej. Poza zaprezentowanymi rozwiązaniami pozostaje do doprecyzowania zostaje wiele kwestii pobocznych. Przykładowo do logowania możemy użyć serwisu Cloud Watch. To właśnie Cloud Watcha użyjemy także do monitorowania naszych zasobów oraz podnoszenia odpowiednich alarmów gdy przykładowo będziemy mieli do czynienia z jakimś problemem. Nie chcemy przecież by tak błache rzeczy jak np. brak pamięci na serwerze, błęd w logice serwisu czy tego typu sprawy zaprzepaściły nasz cały wysiłek i popsuły wizerunek pogromcy Netflixa.
Do przesyłu danych może przydać się Kinesis streams. Autentykacja użytkowników może przebiegać w Cognito. Potrzebujemy też dobrego cache-a, Amazon ElastiCache, poratuje. A no i nie obędzie się bez kontroli tego co który serwis może robić a czego nie może zrobić. Tu do gry wkracza IAM. Na tym chyba poprzestanę 🙂
Z pewnością tego typu przekrojowa architektura może nieco odstraszać, aczkolwiek pozwala sobie jednak zdać sprawę jak skomplikowane tworzenie systemów może być gdy nie mamy do dyspozycji tych gotowych serwisów i chcielibyśmy implementować skalowalny system przy pomocy softwareu instalowanego na naszych maszynach.
Co to dla nas znaczy i w czym pomaga to narzędzie? Najprościej będzie wytłumaczyć na przykładach. W końcu jeden przykład jest warty więcej niż 1000 słów czy jakoś tak.
Przykłady
Interaktywne wyszukiwanie
Zacznijmy od najważniejszego, wyszukiwanie odbywa się w sposób interaktywny tzn. zmiana naszego zapytania wpływa od razu na wyświetlane wyniki! Sprawia to, że wyszukiwanie jest po prostu super-wydajne!
Otwieranie pliku
Wyobraźmy sobie, że potrzebuję otworzyć jeden z plików źródłowych z poziomu konsoli. (jak on się nazywał…)
Załatwione. Jeżeli dana fraza nam nie pasuje możemy strzałkami poruszać się w górę i w dół by wybrać to czego szukaliśmy.
Użycie wyniku w pipeline-nie
Przeszukiwanie plików otwiera przed nami morze możliwości. Nic nie stoi na przeszkodzie by wykorzystać rezultat wyszukiwania w fzf i przykładowo otworzyć wyszukany plik w wybranym edytorze.
fzf | ? { edit $_ }
Potrzebujesz przeszukać pojedyncze linie tekstu w ten sam sposób? Przekierowywujemy tekst do fzf i mamy to!
To tak na prawdę najpopularniejszy przypadek użycia fzf. Zobacz jak wygodne jest teraz przeszukiwanie pliku.
Jeżeli szukasz jakiegoś kawałka kodu i chcesz to zrobić w sposób interaktywny to fzf ułatwi sprawę
Jeżeli znudzi nam się standardowy wygląd fzf, mamy też całkiem spore możliwości manipulacji np
Zagłębiając się w bibliografiach mądrych ludzi tego świata można dostrzec jedną, na prawdę zadziwiającą, rzecz. Wielu z nich, ba, większość z nich odznacza lub odznaczała się wiedzą z jednej strony głęboką, ale z drugiej strony też bardzo szeroką. Z jednej strony jest to banał, w końcu, właśnie dlatego uznajemy ich za szczególnych. Z drugiej strony można się zastanowić, jak ktoś kto miał te same 24 godziny podczas doby osiągnął wyniki diametralnie różne od innych?
Elon Musk
NORAD and USNORTHCOM Public Affairs / Public domain
Weźmy takiego Elona Muska. Mało kto odważy się zakwestionować jego umiejętności inżynierskie, ale z drugiej strony jest on też operacyjnym mózgiem i przedsiębiorcą stojącym za sukcesem firm takich jak PayPal, SpaceX czy Tesla. Spójrz na jego życiorys, tak na prawdę zaangażowany był w jeszcze więcej projektów!. Jeżeli spojrzymy na spektrum wiedzy potrzebnej do stworzenia tych trzech firm, branża finansowa, kosmiczna i samochodowa. To na prawdę niełatwe i niebywale zróżnicowane tematy. W jaki sposób Musk kultywuje dobre praktyki nauki? Ciekawą rzecz napisał w AMA (Ask Me Anything) jakie dał Reddit. Otóż wspomniał, że dla dla niego wiedza ma budowę drzewa gdzie dopiero gdy masz dobrze opanowane podstawy, czyli twój pień i grube gałęzie wiedzy, możesz zacząć dodawać cieńsze gałęzie i liście, nigdy na odwrót!
Leonardo da Vinci
Leonardo da Vinci / Public domain
Innym przykładem może być, ikona i symbol „człowieka renesansu” czyli Leonardo da Vinci. Wystarczy spojrzeć na jego stronę na wikipedii: „włoski malarz, rzeźbiarz, architekt, filozof, muzyk, poeta, odkrywca, matematyk, mechanik, anatom, geolog”. Tak, to wszystko o jednej i tej samej osobie! To właśnie jemu przypisuje się cytat:
The noblest pleasure is the joy of understanding.
Leonardo da Vinci
Co możemy przetłumaczyć jako, „najszlachetniejszą przyjemnością jest radość zrozumienia”. Zauważ, że nie chodziło o radość wynikającą z tego, że wydajemy się mądrymi, nie chodziło o radość wynikającą z czytania, chodziło o radość ze zrozumienia!
Richard Feynman
Unknown author / Public domain
Czytając książkę „Pan raczy żartować, panie Feynman!” rzuciło mi się w oczy jak wielką wagę Feynman przywiązywał do zrozumienia problemu a nie uczenia się formułek. Jak on to określił, nie można nazwać nauką przekładania jednego tekstu na drugi. Nie można nazwać nauką tłumaczenia terminu na jego definicję, bo nie prowadzi nas to do niczego co możemy potem spożytkować. Było to zwłaszcza widoczne podczas jego pobytu w Brazylii gdzie nie mógł się nadziwić tamtejszemu sposobowi edukacji i bezsensownością zakuwania formułek przez studentów. Najciekawszą w tym wszystkim jest to jak bliskie jest to moim doświadczeniom z polskim systemem edukacji.
Wjeżdża koherencja
W jaki sposób posiadając jedno życie, 24 godziny w ciągu doby, osiągnąć takie rezultaty by wszyscy uważali cię za kogoś o szczególnych umiejętnościach? Jak to się dzieje, że jedni nie mogą osiągnąć mistrzostwa w jednej dziedzinie, podczas gdy inni osiągają je w wielu dziedzinach? Jedną, chociaż na pewno nie jedyną, odpowiedzią jest silna koherencja wiedzy. Ten jeden czynnik pozwala na zastosowanie dźwigni i przekładanie efektów nauki z jednej dziedziny do drugiej.
Do słownika zaglądam rzadko 😛 Tym razem zdecydowałem się na ten krok. Co mówi SJP na temat tego czym jest koherencja?
„Koherencja – spójność wewnętrzna myśli, teorii lub ich wzajemna zgodność”.
Bardzo mi się podoba ta definicja! Problem w tym, że wydaje się nieco abstrakcyjna. Od siebie dodam jeszcze taką bardziej praktyczną:
Koherencją wiedzy możemy określić stopień w jakim nasza wiedza jest spójna i pełna. Im większa koherencja tym mocniejsze podstawy ma nasza wiedza oraz tym mniej w niej fundamentalnych braków. O wiedzy koherentnej mówimy wtedy gdy jesteśmy w stanie uczyć się poprzez wiązanie nowych faktów z wiedzą, którą już posiadamy. Traktujemy kolejne gałęzie wiedzy jako część całości a nie jako luźno powiązany zbiór faktów. Posiadamy wiedzę na temat natury rzeczy, nie tylko rozumiemy znaczenie poszczególnych elementów, ale i znamy powiązania między nimi.
Przykładowo wiemy nie tylko czym są wskaźniki finansowe takie jak P/E, CAPE czy EBITDA, ale także rozumiemy jakie są implikacje z ich zmiany. Dodatkowo potrafimy zrozumieć jak zmiany tychże wskaźników wpływają na wskaźniki finansowe przedsiębiorstw w okresie krótki jak i długim. Jesteśmy w stanie wyróżnić efekty pierwszego rzędu i efekty drugiego rzędu (eng. first-order effects and second-order effects)
Koherencja w edukacji
Brak koherencji wiedzy to jeden z problemów dzisiejszej edukacji. Dlaczego? Obecne metody nauczania w szkołach są oderwane od rzeczywistości i praktyki. Ucząc się przede wszystkim abstrakcji w oderwaniu od praktycznej aplikacji nabywamy groźnego syndromu niespójnej wiedzy. Taka wiedza jest niesamowicie niebezpieczna z kilku powodów. Najważniejszym jest obniżenie motywacji do zdobywania nowej wiedzy. Tylko poprzez zdobywanie jednocześnie wiedzy praktycznej możemy widzieć rezultaty nauki, łatać luki w zrozumieniu konkretnych tematów i rozwijać się. To wszystko prowadzi też do złych nawyków, gdzie zdobywanie wiedzy jest celem samym w sobie i nie sprzyja umiejętności używania wiedzy.
Wiedza koherentna
Jakie są oznaki zdobywania wiedzy w sposób koherentny?
Potrafimy wykorzystać zdobytą wiedzę w zdobywaniu praktycznych umiejętności
Uczymy się znajdować analogie pomiędzy dziedzinami
Ucząc się budujemy podstawy na których kładziemy kolejne cegiełki dzięki czemu nie mamy do czynienia z chwiejną konstrukcją a specjalistyczną wiedzą i umiejętnościami.
W rezultacie kultywujemy zdrowe podejście w którym ciekawość prowadzi do chęci zdobywania wiedzy. Rozwijamy praktyczne umiejętności, a nauka daje rezultaty.
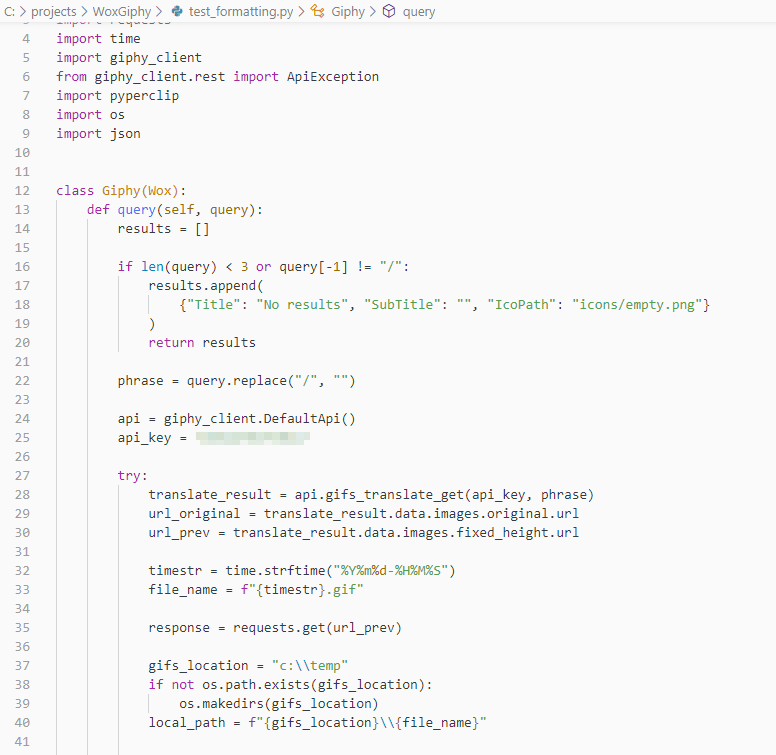
Co jeżeli powiedziałbym ci, że zatrudnię dla ciebie kogoś kto pomoże utrzymać twój kod w pythonie w odpowiednim porządku? Ten ktoś zajmie się twoimi standardami. Jeżeli pracujesz w zespole programistycznym to znacznie ułatwi ci kooperację z innym, przyspieszy code review i ogolnie przyspieszy pracę. Przedstawiam Pana black https://github.com/psf/black robiącego tytułowy black magic
Początki
W najprostszym wypadku do użycia black magic wystarczy nam wywołanie prostej komendy:
black <<file name>>
Jeżeli nie masz jeszcze biblioteki to przedtem jeszcze:
pip install black
W rezultacie zobaczymy coś takiego:
Pozwoli nam na sformatowanie niechlujnego wyglądu kodu:
w coś co spełnia założone reguły:
Co potrafi Pan black?
Domyślnie black robi takie rzeczy jak:
standaryzacja użycia cudzysłowów
usunięcie zbędnych nawiasów np. z warunków if (condition):
usunięcie zbędnych pustych linii
umieszczenie argumentów wywołania funkcji, w miarę możliwości, w jednej linii
i wiele innych
Jak przystało na przydatne narzędzie black może być też konfigurowany tak by sprostać potrzebom ludzi pracujących z innymi standardami.
Przykładowo umieszczenie w pliku pyproject.toml:
[tool.black]
line-length = 75
zgodnie z intuicją sprawi, że nasz kod będzie przyjazny węższym ekranom:
Co jeszcze oferuje black?
Możesz skonfigurować integrację z systemem kontroli wersji i formatować kod przy użyciu pre-commit hooka.
Zignorować formatowanie części plików jeżeli nie chcesz do nich aplikować standardów
Użyć integracji z twoim ulubionym edytorem (Visual Studio Code, SublimeText 3, Vim, PyCharm)
Integracja z Visual Studio Code
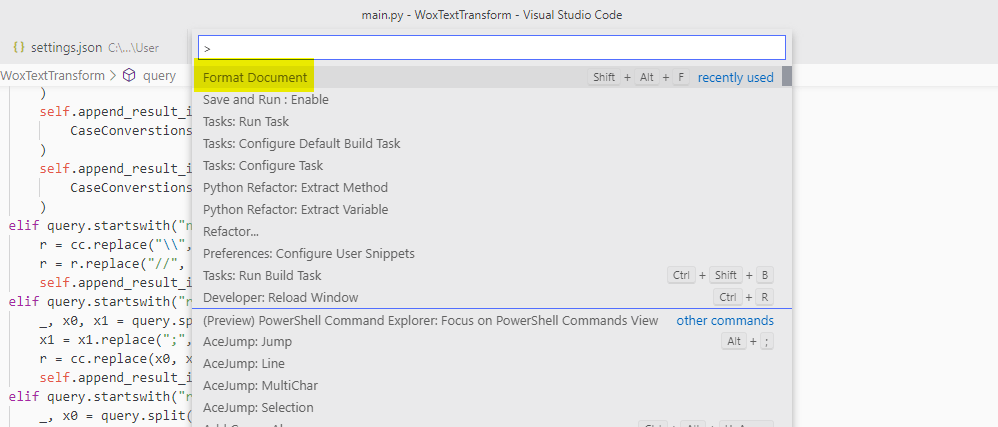
Jako, że sam używam Visual Studio Code to pokażę, też w jaki sposób można z poziomu Visual Studio Code używać black. Wystarczy zrobić 2-3 proste czynności:
Zakładam, że masz już zainstalowaną bibliotekę black. Jeżeli nie to pip install black.
Do naszych ustawień visual studio code (plik settings.json) dodajemy wpis: "python.formatting.provider": "black"
Za pomocą polecenia Format Document hmmm… formatujemy dokument 😉 Można też użyć skrótu Shift+Alt+F
Jeżeli chcemy w jakiś sposób sparametryzować formatowanie black’a i użyć niestandardowych ustawień formatowania, to w tym samym pliku używamy np. "python.formatting.blackArgs": ["--line-length", "90"]
Profit
Chyba nie muszę pisać ile czasu może nam to zaoszczędzić, jeżeli porównamy to z ręcznym formatowaniem kodu 🙂
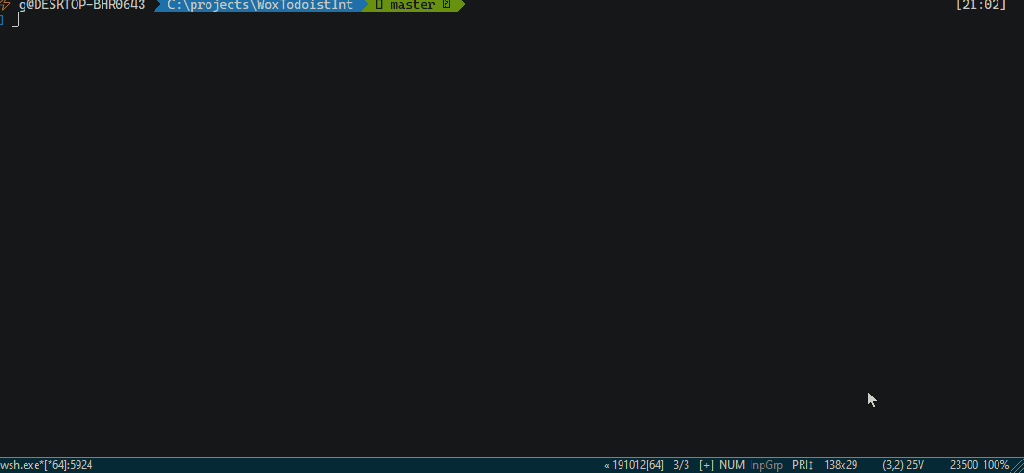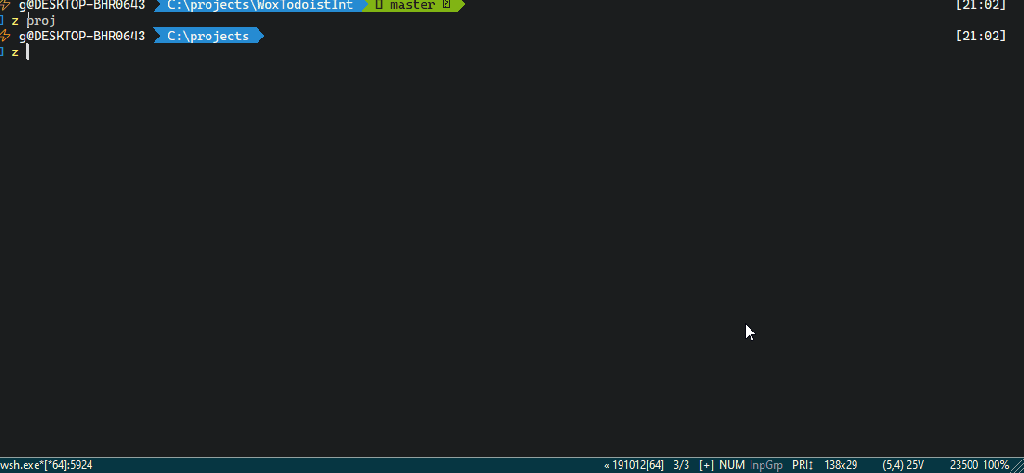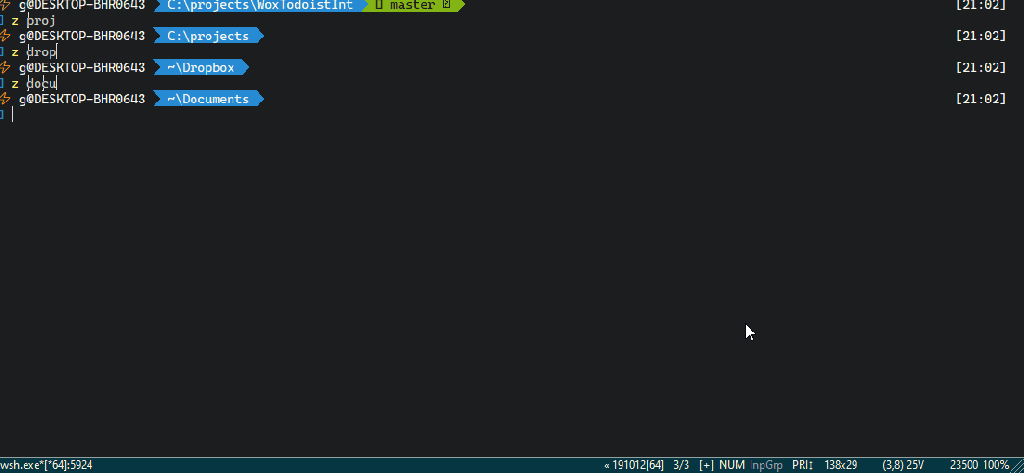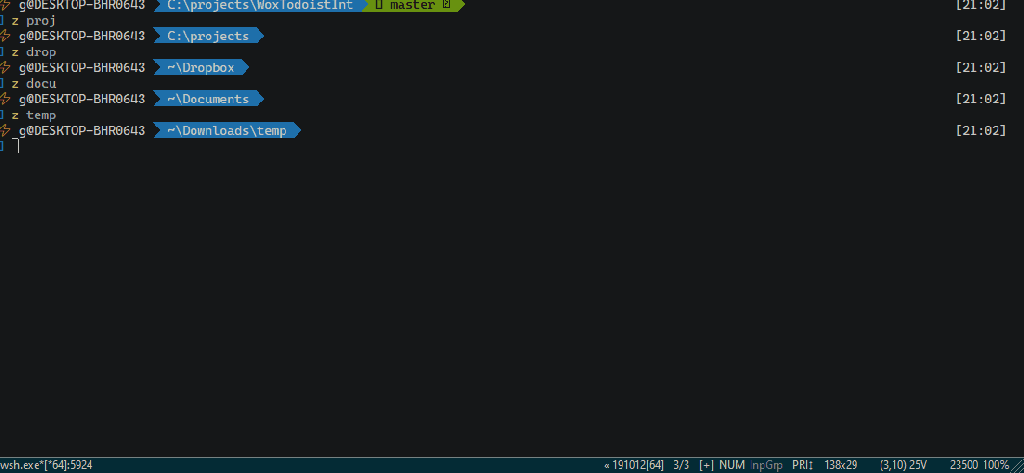
Dzisiaj będzie o trickach związanych z powershell-em. Przez dłuższy czas rozważałem różne możliwości przemieszczania się po strukturze folderów.
Zlocation
O ile część problemów rozwiązuje narzędzie typu https://github.com/vors/ZLocation i możliwość szybkiego „skakania” po folderach najczęściej przez nas używanych:
(jak widzie sporo przyspiesza to pracę z konsolą) to w pewnych sytuacjach przydaje się jeszcze jedno ułatwienie.
Słownik
Jeżeli
nie pamiętamy nazwy folderu który chcemy wyszukać
chcemy przekazać gdzieś ścieżkę do jakiegoś naszego skryptu bądź też programu z zachowaniem elastyczności, możliwości jej późniejszej zmiany czy to na tym samym komputerze bądź też na komputerze innego użytkownika.
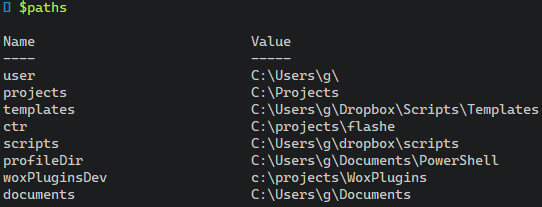
potrzebujemy czegoś innego. Najlepszym rozwiązaniem które do tej pory wymyśliłem to dedykowane zmienne w Powershell razem ze słownikiem, który je agreguje.
Tytułem wstępu, cały kod, który pojawia się poniżej ładujemy do naszego pliku $PROFILE w Powershell.
Możesz zapytać. I słusznie. Równie dobrze możemy użyć zmiennych środowiskowych jeżeli np. dany skrypt ma działać u kogoś na komputerze. Jeśli chodzi jednak o nawigację to słownik ma 2 duże przewagi:
Szybciej można użyć danej zmiennej w Powershell (tip: użyj Tab completion)
Słownik może mieć tylko te wartości, których używasz na co dzień, dzięki temu nawigacja jest prostsza.
Na koniec proponuje jeszcze załadować nasze dane ze słownika do zmiennych środowiskowych, tak by rzeczywiście można było używać ich w przenośnych skryptach.
Zapomnijmy na chwilę o mikroserwisach pomimo, że mowa o nich w tytule. Wyobraźmy sobie serwer udostępniający dane o użytkownikach pewnego portalu społecznościowego. Niech będą to szczegółowe dane takie jak imię, nazwisko, ale i ostatnie aktywności na portalu czy też opublikowane posty. Taki serwer udostępnia pewnie jakieś API do pobierania tych informacji zgromadzonych w bazie danych. Powiedzmy, że mamy metodę GetPerson(), która to wykorzystując warstwę aplikacyjną odpytuje repozytoria o dane osoby z innej tabeli wczytujemy ostatnie aktywności a jeszcze z innej ostatnie posty użytkownika. W tej sytuacji aplikacyjna kliencka odpytuje nasze API, odpowiednio prezentuje dane i mamy to.
Wróćmy do mikroserwisów. Sytuacja nieco komplikuje się, bo dane interesujące aplikacje klienckie są rozsiane po różnych zakamarkach systemu. W ostateczności moglibyśmy w końcu dociec gdzie co jest zlokalizowane, w jakim formacie musimy odpytać dany mikroserwis (albo zmusić wszystkie do wystawiania Rest API itd.), ale rodzi to wiele problemów:
Co z uwierzytelnianiem? Czy każdy mikroserwis musi się tym przejmować?
Jak zminimalizować wpływ zmian w strukturze i funkcjonalności mikroserwisów na działanie klientów?
Co ze skalowaniem? Co jeżeli zwiększamy liczbę instancji danego serwisu? Kto decyduje o adresie docelowym zapytania?
Załóżmy, że zmieniamy odpowiedzialności mikroserwisów, wprowadzamy nowe, usuwamy stare. Jakkolwiek zmieniamy wewnętrzną strukturę systemu. Jak wyeliminować zmiany po stronie klientów API?
Rozwiązanie
Jak można się tego spodziewać istnieje rozwiązanie, które upraszcza większość z problemów, które mogą się pojawić w kontekście interakcji między klientem a serwerem w architekturze mikroserwisów. Możemy wprowadzić dodatkowy komponent pośredni między warstwą aplikcji, a aplikacją kliencką, a jest nim API Gateway.
API Gateway to pewien rodzaj reverse proxy. Jego rolą jest odizolowanie reszty mikroserwisów od kwesti związanych z obsługą zapytań z aplikacji klienckich, a więc będzie on przekierowywał zapytania z klienta do odpowiednich serwisów. Odnosząc się do analogii z tytułu posta, API Gateway to drzwi wejściowe do naszego systemu. Z punku widzenia aplikacji klienckiej wszystko za tymi drzwiami jest ukryte i jeżeli nie podamy jej czegoś przez te drzwi to tego nie dostanie. Nie pozwalamy na wejście oknami czy też przez balkon.
Zalety
Co dzięki temu zyskujemy?
Klient nie troszczy się ani o lokalizację mikroserwisów, ani o to w którym mikroserwisie zlokalizowany jest interesujący go zasób, ani o to ile instancji danego mikroserwisu jest dostęne, ani o to czy zmienimy strukturę mikroserwisów, ba, on nie troszczy się o to czy ma doczynienia z mikroserwisami w ogóle!
Umożliwiamy odpytywanie systemu przez wygodne API, które może być dostosowanie API pod konkretnych klientów, bez konieczności implementacji tego w każdym mikroserwisie.
Mamy tylko jeden punkt w którym uwierzytelniamy użytkownika.
Możemy łączyć, filtrować, sortować i w różny sposób manipulować danymi w taki sposób by dostosować je do oczekiwań aplikacji klienckiej.
Pozwalamy mikroserwisom rozmawiać między sobą w formacie, który jest dla nich wygodny, ponieważ nie ma to wpływu na klienta
Możemy wersjonować API wystawione przez nasz Gateway w jeden sposób, a API wewnętrzne wykorzystywane przez mikroserwisy w naszym systemie w całkowicie inny sposób.
Łatwiejsze zastosowanie load balancingu. W specyficznym przypadku API Gateway może być load balancerem.
Łatwiej zastosować blue/green deployment. Dzięki Gateway’owi po deployu możemy przekierować ruch ze starych do nowych serwisów i staje się to bajecznie proste.
Wady
Jakie mamy minusy tego rozwiązania:
Jako, że z natury mamy teraz pojedynczy punkt dostępu do systemu, w przypadku niedostępności tego serwisu, cały system staje się niedostępny. Jeżeli mamy problem z wydajnością w API Gatewayu wpływa on w znacznej mierze na cały system.
Dodajemy następny komponent w systemie
Minimalnie wydłużony czas względem bezpośredniego zapytania klient-mikroserwis
Miałem to szczęście, że dość szybko zostałem zaznajomiony ze wzorcem API Gateway dzięki czemu uniknąłem problemów, które przedstawiłem w początkowej części artykułu.Myślę, że zestawienie wad i zalet pokazuje tutaj jaki potencjał w nim drzemie zwłaszcza przy rozproszonych systemach.









 source:Photo by
source:Photo by 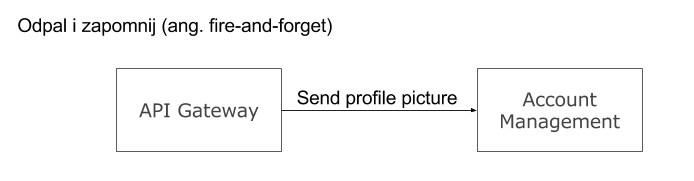

 Source:Photo by
Source:Photo by 














_(cropped).jpg)